Datasets#
Climate risk assessments (CRA) combine datasets on hazards, exposure and vulnerability, both under current as well as future climatic and socioeconomic conditions. Here we provide details of different pan-European datasets that can form the basis of CRA, all of which are publicly available under an open-access license. These examples of hazard, exposure, and vulnerability datasets provide an overview of data currently used in CRA or for potential use in CRA.
Fig. 8 Illustration created by Scriberia with The Turing Way community. CC-BY 4.0. 10.5281/zenodo.3332807#
Hazard data#
Report on hazard tools of relevance to the CRA Toolbox
Hazard is essential to understand the potential intensity, frequency, and spatial distribution of climate risk.
In addition to the following summary of hazard datasets, more comprehensive overviews of pan-European hazard datasets with technical specifications are provided:
Exposure and vulnerability data#
Report on pan European vulnerability and exposure projections
Exposure and vulnerability can be classified based on their social and physical characteristics (Fig. 9). This aligns with the United Nations Office for Disaster Risk Reduction’s (UNDRR) Risk Information Exchange (RiX), which catalogues data on the three risk drivers. The social dimension includes the population exposed to climate hazards, as well as demographic (e.g. age, gender) and socioeconomic (e.g. income, poverty) characteristics that determine its vulnerability (Cutter et al., 2003; Rufat et al., 2015). The physical dimension includes exposed assets such as settlements, infrastructure, buildings, and environmental resources along with their characteristics such as type (e.g. power stations versus schools; residential versus commercial buildings), material (e.g. wood versus brick buildings), or land use (e.g. agricultural versus industrial land) (Cremen et al., 2022; Huizinga et al., 2017; Nirandjan et al., 2022, 2024).
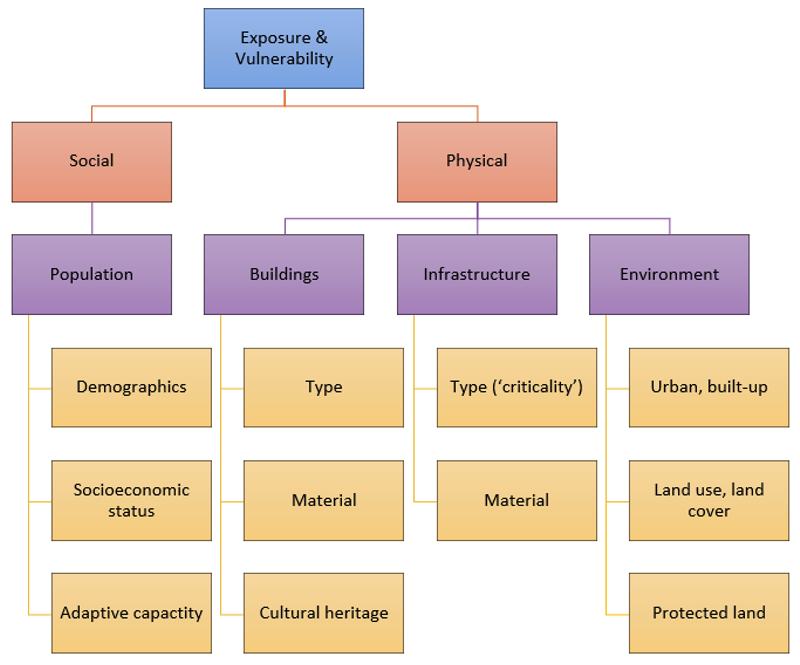
Fig. 9 Classification of exposure (purple) and vulnerability (yellow) characteristics in CLIMAAX (own illustration).#
In the following sections on exposure and vulnerability datasets, a more detailed description of a selected set of data from the full database is provided; datasets can be selected based on data needs in terms of spatial and temporal resolution and the underlying acquisition or modelling approach. Additional technical details of the example datasets are provided along with relevant information for using the data in CRA, including datasets that reflect current as well as future conditions.
Tip
It is worth noting that all datasets have different advantages and disadvantages which make them more or less suitable for a specific CRA (see Uncertainties in exposure and vulnerability datasets). These uncertainties need to be kept in mind when interpreting the results of a CRA based on the datasets described here, particularly at local and regional scales. While results will provide a reasonable first-order assessment of risk hotspots, locally developed data, for instance, from national or regional statistics offices, are needed for a more refined analysis that can inform decision-making. In this context, it is important that the data used are approved and trusted by local stakeholders (Gramberger et al., 2015; Reimann et al., 2021).
See also#
Climate Risk STAC is a catalog of hazard, exposure and vulnerability datasets, grouped into a) climate processes (i.e. hazard) and b) socioeconomic processes (i.e. exposure and vulnerability).